As part of a formal research collaboration with SASB to contribute to the improvement of SASB’s Human Capital standards, in late 2019 Rights CoLab teamed up with the Data for Good Scholars (DfG) Program of Columbia University’s Data Science Institute to find evidence of the financial materiality of labor-related human rights risks using natural language processing (NLP) and other machine learning data science methods.
In consultation with the project Expert Group of international labor experts as well as AI and human rights professionals,[1] we identified two workstreams to address the gaps in SASB data collection for the first published standards: the “Addition Workstream” and the “Extension Workstream.” Each workstream addresses a criterion of SASB’s definition of financial materiality. The Extension Workstream examines investor interest through Form 10-Ks, proxy statements, and earnings calls; the Addition Workstream examines the financial impact of corporate labor-related practices, primarily through news sources.
Our first project update describes our methodological approach to building text processing models, including the selection of keywords and phrases for machine learning and datasets for building the data model. Since our Spring 2021 update, the data science team has tested different approaches for each of the two workstreams to identify the highest performing models that meet a high accuracy threshold. This update describes those efforts and lays out the next steps for the research.
Summer 2021 members of the DfG project team are: Raiha Khan, Jiongxin (Jessie) Ye, Uttara Ravi, Zhuoyan Ma, Isha Shah, Lawrence Lai, and Emmanuel Murungi Mwebaze. The DfG work is led by Rights CoLab Co-Founders Joanne Bauer and Paul Rissman, who together with the Expert Group provide subject matter guidance. DfG Program Coordinator Dr. Ipek Ensari supervises the data science methods selection and implementation.
Update Oct 19: Since first publishing this report in September 2021, we updated the intensity model for company reporting of diversity in their Form 10-Ks. The text and chart under section, “Intensity: Average number of paragraphs that contain diversity terms per Form 10-K,” and Appendix C have been updated.
Introduction
During Summer 2021 we made significant progress on the Extension and Addition Workstreams, and began direct engagement with SASB research analysts as they considered their next steps on the Human Capital project – in particular their first tranche of standards revision related to Diversity and Inclusion.
For the Extension Workstream, we compiled evidence of investor interest across a group of industries for the SASB topic “Employee Engagement, Diversity, and Inclusion,” which the SASB Standards Board has identified as one of its priority General Issue Categories (GICs) for Human Capital standards revision. We used a heuristic method, after testing several potential data processing methodologies.[2] We applied this method on a dataset of corporate financial filings – Form 10-Ks – which we built with the aid of SASB’s own labeled data set. We also began applying the same method to other datasets, including proxy statements and earnings calls.
In the Addition Workstream, we explored datasets from the GDELT Project, a free, open platform initiative monitoring the world’s broadcast, print, and web news in over 100 languages. These datasets provided a larger and more comprehensive corpus on which to apply the odds-ratio test, a method for testing connection between actions and outcomes that we began testing on a smaller dataset of news articles in Spring 2021. We continued refining the inputs to our odds-ratio test, which defines labor-related corporate practices as the action and risks that have financial implications, such as fines, boycotts or lawsuits.
The following update describes the methods and findings of this work.
The Extension Workstream
In the Extension Workstream, we are seeking evidence to justify the extension of SASB’s Human Capital Management (HCM) disclosure topics, which currently apply only to some SASB industries, to a broader range of industries. We focus on identifying investor interest in a given topic for those industries not currently containing that indicator, as denoted by the white spaces in SASB’s materiality map.
Over Summer 2021, we developed our heuristic research method which we first experimented with in Spring. This approach involves searching within each paragraph of a document for keywords that identify the paragraph as being relevant to the topic being researched. By identifying the number of paragraphs that discuss a topic, it provides a signal for how prominent that topic is for companies and investors. The keywords for each heuristic are developed through unsupervised machine learning methods and with feedback from the Expert Group. We began with the topic Employee Engagement, Diversity & Inclusion (EDI) since the SASB Board had recently decided upon this topic as its first priority for the Human Capital Research Project.
In the current SASB standards there are 12 industries that have an EDI disclosure metric, and seven accounting metrics within the GIC.[3] Because the heuristic method requires word specificity, we needed to research one metric at a time. We started by focusing only on industries with this SASB accounting metric:
Percentage of gender and racial/ethnic group representation for executive management, non-executive management, professionals, technical staff, and all other employees.
This metric (which we will refer to as the “gender/race representation” metric) is most directly related to racial and gender equity, and is the most prevalent metric across the twelve industries that have an EDI standard, with nine industries requiring disclosure on this metric.
The 10-K dataset
We first applied our heuristic method to Form 10-Ks. In financial filings to the U.S. Securities and Exchange Commission (SEC), which consist of Form 10-Ks and Form 10-Qs (annual reports and quarterly reports), companies are required to report their “risks factors” (Item A1). The 10-K dataset we built, based upon a labeled Form 10-K data set that SASB had created and shared with us, contains approximately 39,000 Form 10-Ks, representing the Form 10-Ks filed by every US-domiciled company from 2013 to 2020.
Form 10-Ks provide just one measure of investor interest, yet it is a valuable one in that the filings represent a corporate view of the risks that investors find most salient. Even if companies are conservative and disclose no more than the necessary minimum, we can consider the disclosures in our Form 10-K data set as unambiguous risks.[4]
Form 10-Ks are also a good starting point for this research because:
- 10-Ks are in a single format on Electronic Data Gathering, Analysis, and Retrieval of the US Securities and Exchange Commission (EDGAR) making it easy to retrieve a wide sample of filings, including across industries and going back in time;
- SASB itself deems 10-Ks to be a highly valuable measure of investor interest; therefore, SASB is likely to be persuaded by this evidence; and,
- SASB had a labeled dataset for Form 10-ks, which it could share with us.
Additional datasets: Proxy statements and earnings calls
Proxy statements are documents that the SEC requires companies to provide to investors in advance of annual shareholder meetings. Earnings calls are regular quarterly calls that companies have with investors after the release of their quarterly performance results. As our objective is to build an evidence base that is representative of investor interest, proxy statements and earnings calls can complement Form 10-Ks.
Proxy statements contain shareholder proposals, each of which is introduced by an individual or group of shareholders that have owned at least $2,000 worth of stock for a year.[5] These shareholder proposals indicate investor interest which may extend beyond the topics covered in a company’s Form 10-K.
Earnings calls tend to be highly scripted and until recently were dominated by hedge funds and other short-term investors. Increasingly, however, environmental, social and governance (ESG) topics are being raised on these calls.[6] As such, we are creating an earnings calls database of transcripts from 2019-2021.
The heuristic method
The heuristic method involves searching for select keywords in a text, sometimes under the condition that they co-occur with one or more other keywords so that we can be assured through a better understanding of the context that it is relevant.[7] For example, for our “diversity” heuristic, we searched our corpus of Form 10-Ks for any paragraphs containing the words “diversity” or “inclusion” and any of their roots, along with other terms that suggest the subject of a paragraph is in fact diversity or inclusion. Pairing terms for context ensures that any paragraphs we find using this approach are about diversity in relation to the workforce, rather than other common uses of the word (e.g., having a “diverse” portfolio).
We defined a set of “benchmark” industries based on the SASB materiality map. The benchmark comprises the nine industries within the current SASB standard that contain the gender/race representation accounting metric, as noted above. We treated the three industries that have an EDI standard but not this particular metric as “non-benchmark” industries. An equal or higher share of companies in non-benchmark industries discussing diversity terms compared to an average of the benchmark industries would suggest that those non-benchmark industries should be priorities for extending that accounting metric. See Appendix A for the code for our diversity and inclusion heuristic.
Results from applying the heuristic method: Form 10-Ks
To measure the mentions of diversity and inclusion in Form 10-Ks, we used two measures: ubiquity and intensity. Ubiquity refers to how widespread mentions of our diversity terms are within industries, and is represented by the share of all Form 10-Ks within an industry that have any mention of the terms. Intensity refers to the frequency of mentions of diversity terms by companies within an industry, and is calculated by taking an average of the number of paragraphs per Form 10-K that mention the terms across an industry.
Ubiquity: Share of companies in each industry that mention diversity and inclusion
Examining our Form 10-K dataset, we found that the share of companies in each industry that used terms that we designate as diversity terms remained relatively steady. In 2020, however, the share of companies in each industry that used diversity terms increased markedly, as can be seen in the chart below.
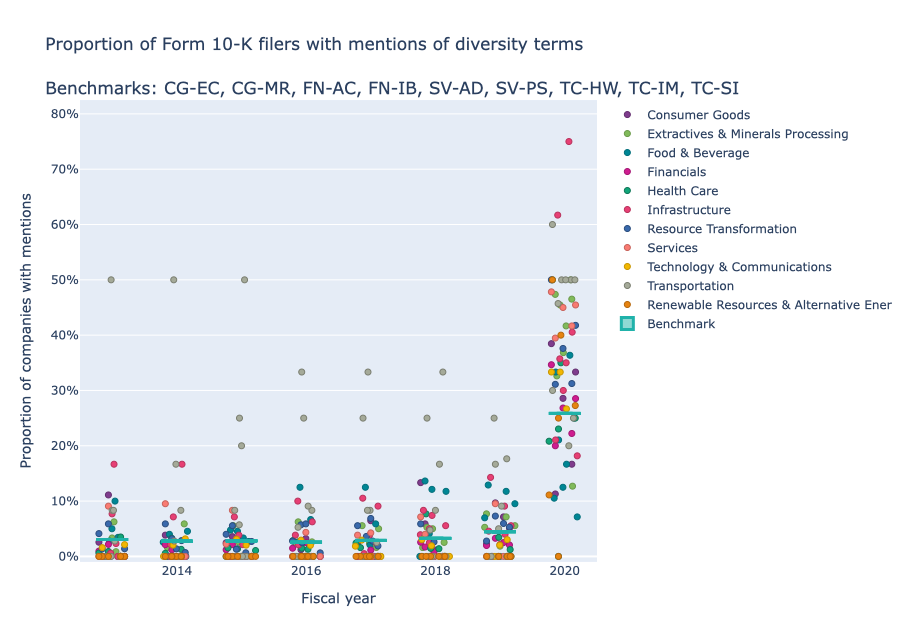 The top 15 industries with the highest share of Form 10-Ks containing diversity terms in 2020 are as follows:
The top 15 industries with the highest share of Form 10-Ks containing diversity terms in 2020 are as follows:
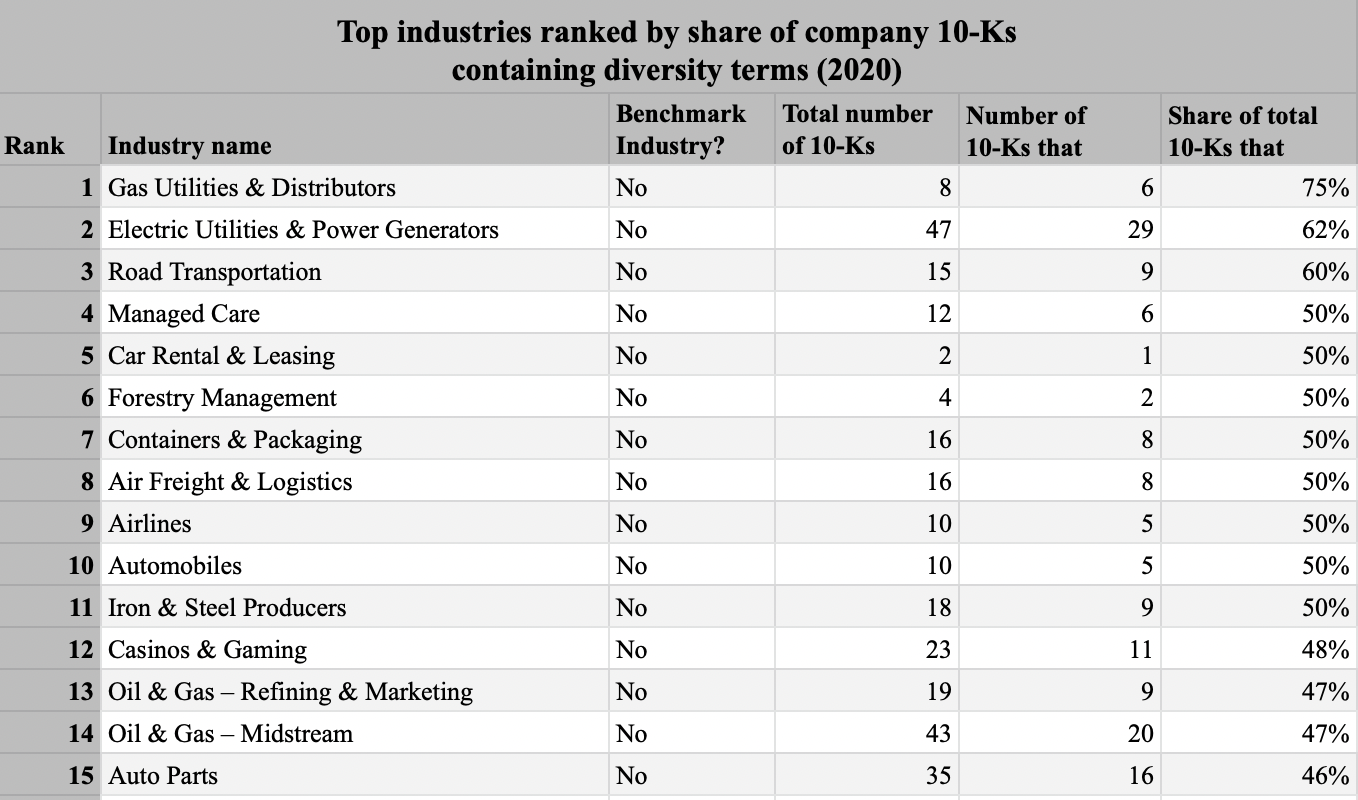
Of all 77 industries, 55 have a share of companies using diversity terms in their 2020 Form 10-Ks that is higher than the benchmark average (23.5%). Twenty-five industries have a higher share of companies using diversity terms in their 10-Ks than the Internet Media & Services industry, which is the grey space industry with the highest share of mentions of diversity terms at 38.2%. These findings suggest that diversity is a material topic for these industries and therefore that they be considered priorities for SASB’s Human Capital standard setting.
Percentage of Form 10-Ks that contain diversity terms, by industry in 2020
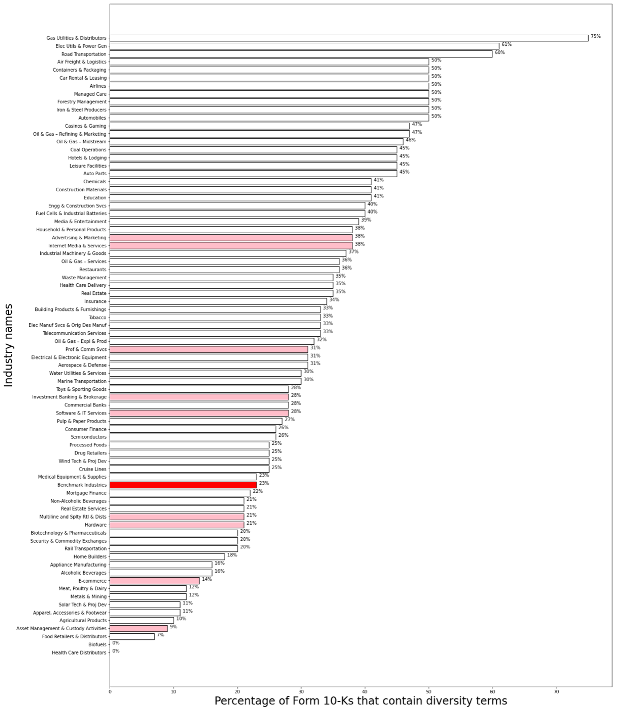
Note: In the above chart, the 77 SICS industries are listed on the vertical axis; the percentage of companies’ Form 10-Ks within each industry that contain diversity terms are represented by the length of the bar. Benchmark industries are highlighted in pink, and the average for benchmark industries is highlighted in red. For a complete list of all industries containing details on the number of Form 10-Ks that met our criteria for each, see Appendix B.
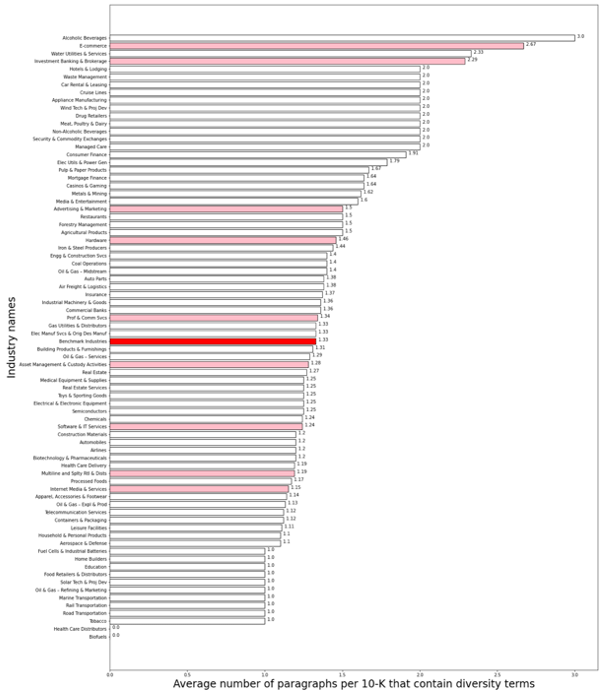
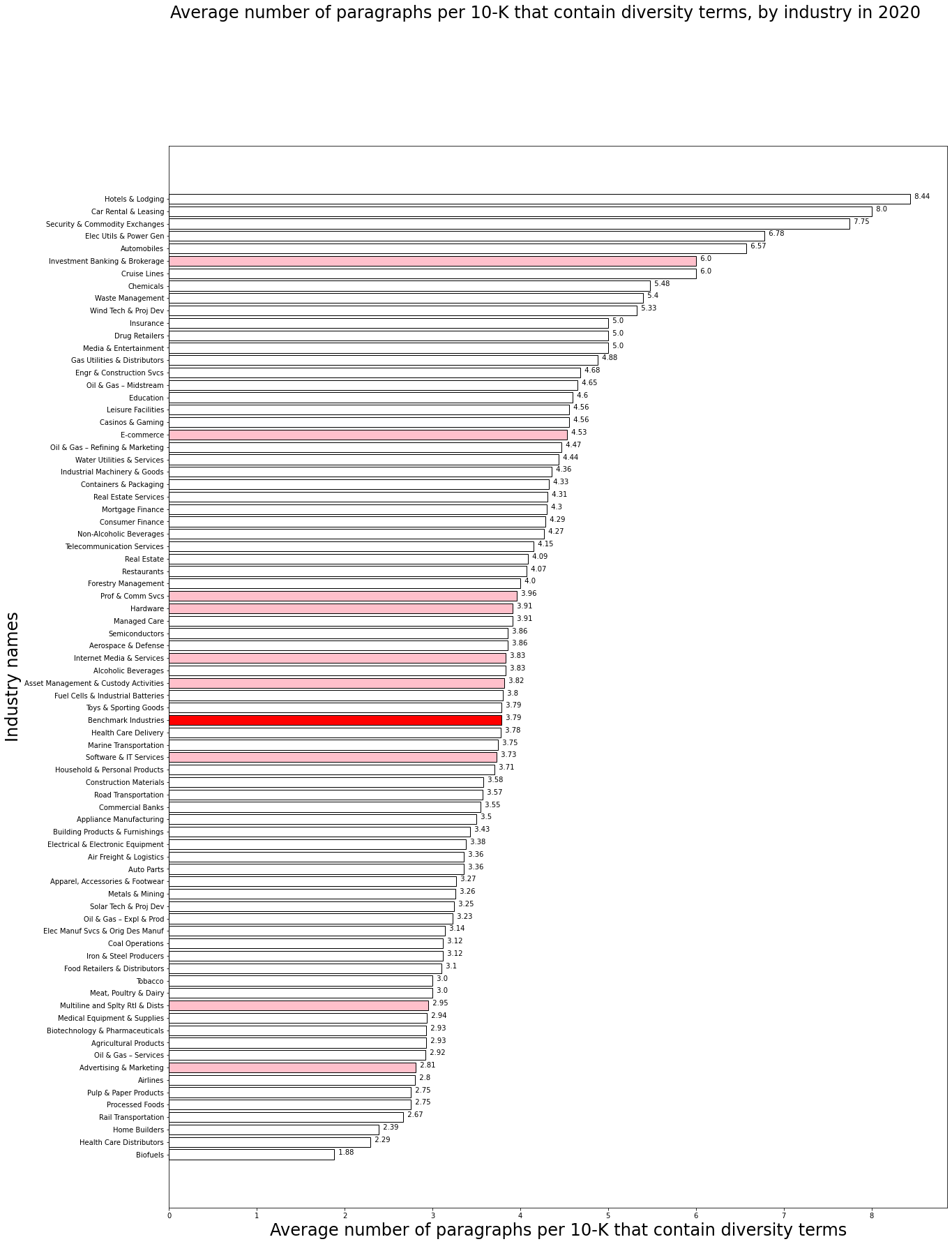
Intensity: Average number of paragraphs that contain diversity terms per Form 10-K
Similar to the ubiquity measure, the intensity measure for diversity and inclusion remained relatively constant from 2013 to 2019, with a sharp increase from 2019 to 2020. The top sectors for the intensity of diversity disclosure include Hotels & Lodging, Car Rental & Leasing, Security & Commodity Exchanges, etc.
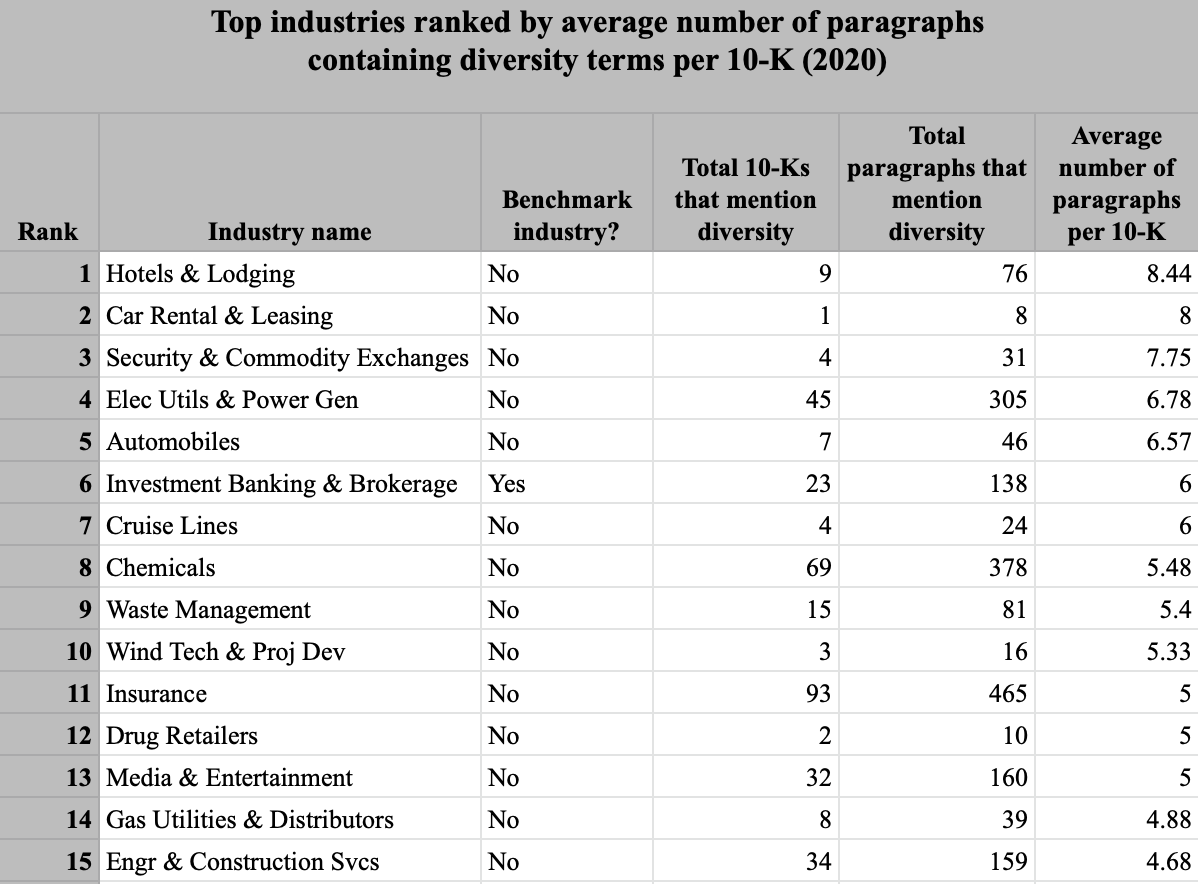
Of all 77 industries, 42 non-benchmark industries have an average number of paragraphs containing diversity terms per Form 10-K that is equal to or higher than the benchmark average (3.79 average paragraphs per 10-K). These industries point to an additional group of priority industries for SASB as it seeks to update its disclosure standards for the Employee Engagement, Diversity, and Inclusion GIC. For a full ranking of the 77 industries on the intensity measure, see Appendix C.
Average number of paragraphs per 10-K that contain diversity terms, by industry in 2020
Applying the heuristic method to proxy statements and earnings calls
The application of the diversity and inclusion in hiring heuristics to proxy statements and earnings calls is ongoing since we added more recent proxy statements to our corpus and downloaded and cleaned the transcripts for all quarterly earnings calls in 2021 Q1. We plan to first apply the same heuristics that we applied to our Form 10-K corpus to see if company use of diversity terms follows similar patterns.
Next steps for the Extension Workstream
Over the next semester, we will continue developing heuristics for other EDI accounting metrics, such as employee turnover and talent retention & recruitment. We will apply these heuristics to multiple data sources, starting with Form 10-Ks and then proxy statements and earnings calls. The combination of these new heurists and data sources will providing supporting evidence to a set of industries for which EDI is financially material as a guide for SASB EDI standard setting.
The work in the Extension Workstream will also support the Addition Workstream’s work by refining the lists of practice and risk terms and searching for evidence of links between them using the GDELT data set (see below). Additionally, to gain further instight into investor interest, we will explore other datasets, including databases of discrimination-related lawsuits and possibly, pending access, some aspect of sell-side analyst reports.
The Addition Workstream
In the Addition Workstream, we seek to identify new relationships between labor rights and SASB criteria for financial materiality across a broad range of SASB industry standards to support the development of new metrics that better reflect human rights risks to companies. As such, these metrics do not currently appear anywhere on the SASB materiality map. With this in mind, our main technical objective for this workstream is to create a corpus of relevant articles to test co-occurrences of corporate practice and risk terms by mining a database of online global news articles. Co-occurrences will point to relationships about the financial materiality of corporate practices among industries, thereby generating supporting evidence for the necessity of these metrics in SASB’s disclosure standards.
The GDELT dataset
GDELT is a global events database supported by Google Jigsaw that monitors news media in over 100 languages from all over the world, and records news stories in a dataset called the Global Knowledge Graph (GKG).[8] Along with the URL of the story, each article contains the date the story was published (the database collects articles from its sources every 15 minutes, and dates back to January 1, 1979) the region of origin, and the “theme” of the story, among other information. Since GKG aggregates news stories from outlets across the world, including those that are only published in non-English languages, it is ideal for investigating topics on a global scale.
Keyword searches on the GKG
The main dataset we used in the Addition Workstream over the Summer 2021 semester was the GKG dataset of the GDELT project. GKG contains several fields that point to the article topic and companies/organizations discussed in the article, which can help us determine the article’s relevance to our study. We focus on determining the correct combination of keyword searches in these fields to produce articles relevant to the topics of interest with a high degree of accuracy. We then identify the industry that each article discusses to generate insight on the materiality of a given corporate practice by industry.
Two useful fields in GKG are the URL and webpage title of each article. The URL of a news article and its title typically suggest its topic, and are therefore useful for querying certain keyword terms. To create our dataset of articles for studying the co-occurrence of risk and practice terms, we started by querying GKG using these two fields, searching for keywords associated with practices that relate to these topics. We also queried these fields for different categories of financial impact or risk. For instance, we started by testing for the topics “grievance mechanisms” and “whistleblower.” To identify all relevant articles, we searched the URL and the webpage title for the following related terms: “whistleblower,” “grievance,” “grievance mechanism,” “anonymous hotline,” and “retaliate.”
Applying the odds-ratio approach
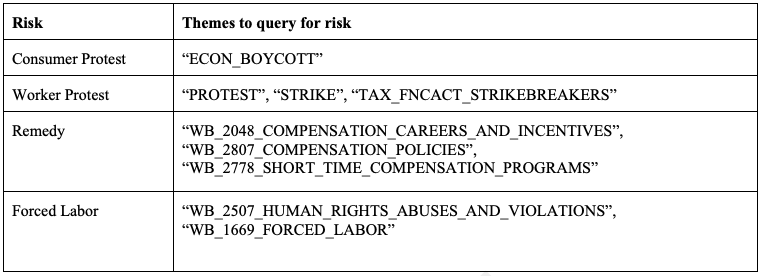
We applied an odds-ratio test on a random sample of 1,000,000 records from the GKG dataset from 2020.[9] An odds-ratio test can be used to determine whether a certain “exposure” variable — meaning a term representing a company practice that we are hypothesizing may be material — leads to a certain outcome or risk for that company. We used article outputs from our keyword search queries to calculate odds ratios to determine whether a given labor-related practice by a firm – for example, the absence or presence of a grievance mechanism – is related to a financially material outcome, such as a protest or boycott.
To prepare for conducting an odds-ratio analysis, we developed a pipeline and code to ingest[10] the GDELT GKG sample, search for various risk and practice terms, and perform the odds ratio test for each practice term. We started testing for co-occurrences of practice terms and risk terms in articles, using the methods that Addition team members had developed in past semesters using a corpus of articles pulled from The New York Times and The Guardian.
While identifying articles with practice-risk co-occurrences to calculate odds ratios, we read through samples of each share of risk term articles within practice term articles. Since articles found solely using keywords in page titles and URLs might not be directly relevant to company practices or company risks, and since GKG provides themes associated with each article, we resolved to improve our methods to query articles relevant to practice/risk term contexts, and we enhanced the corpus by adding themes as an additional dimension to the heuristics to query GKG articles. The next filter we applied is one that identifies whether each record in the GKG dataset implicates a company or an industry, and we used this filter to sort the resulting articles into the appropriate SICS industry. This allowed us to find the odds ratio by industry.
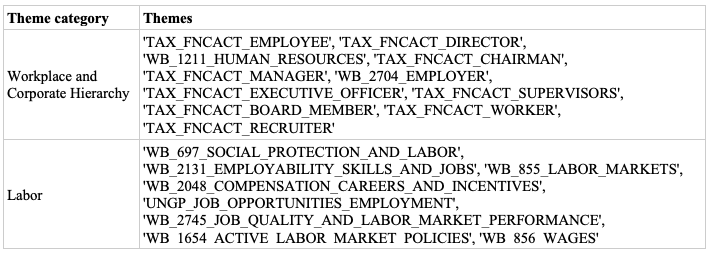
Theme searches on the GKG
Another useful GKG field is the “themes” field. Each article can have multiple themes associated with it, ranging from broad to narrow. We identified the following themes as most relevant to the practices we are searching the dataset for:

Some themes, such as “WB_736_GRIEVANCE_REDRESS_MECHANISM,” return a reasonably high proportion of articles that discuss grievance mechanisms in companies. Other themes can produce results with a high number of articles irrelevant to corresponding corporate practices; such is the case with the theme “DISCRIMINATION_RACE_RACISM,” since discrimination and racism can be presented in the news for many reasons including immigration, hate crimes, etc. This presents us with a stronger need to apply filtering rules to narrow queried articles down to those relevant to company practices, especially in the case of discrimination-related themes, which return a very large number of results.
To determine whether an article mentions a risk, we identified themes to return articles relevant to the risks we are searching the dataset for:
Next, we are devising rules to whittle down the articles returned to only those that are relevant so that we have a pipeline of articles that contain relevant practice or risk terms with 95 percent accuracy or better. So far, these rules entail filtering our query outputs by another set of themes, which we have identified by sampling and reading GKG articles that cover corporate practices. If an article has at least one theme from each of the categories below, the article has a high likelihood of relating to corporate practices:
Company identification
To determine the connection between practice and risk on an industry-by-industry basis, each article must be categorized by the industry that it references. To do this, we use a crosswalk table provided by SASB, which maps the name of a company to its SICS industry. Using this crosswalk and the “organizations” field in GKG, we devised rules and implemented a matching algorithm to identify industries that articles pertain to.

The figure above shows an output from an exploratory phase of matching articles to industries. One of these columns describes the “score” of our GKG organization-to-company match, where scores range from 0.0 (no matching characters) to 1.0 (a perfect match — all characters match).
To identify the company associated with the practice/risk, we first generated these scores for company matches with a score greater than 0.0. Next, we filtered out any ambiguous GKG organizations, such as “young” from the figure above, that do not correspond to a company in our SICS industry crosswalk. Finally, our method takes the company with the highest-scoring organization match, and it maps the article to the company’s industry. Any improvements to this method will improve our accuracy in identifying articles that correspond to specific industries, furthering our work on the odds-ratio analysis front and deriving co-occurrences of corporate practice and risk terms.
Next steps for the Addition Workstream
In the Fall 2021 semester, we will continue writing rules and devising algorithms for identifying articles related to corporate practices and risks in the Addition Workstream, specifically around topics related to worker voice and agency, DEI in the workplace, and other topic areas to be identified through collaboration with the Expert Group.
Having developed a high-accuracy method for selecting news articles, we will continue conducting odds-ratio analysis to observe which corporate practices are leading to risks within specific industries, starting with analyzing practice-risk co-occurrences within industries for which we have the most articles. Through this process we aim to identify the practices that display statistically significant relationships to financially material outcomes and the industries in which these relationships exist. This information will support consideration of human capital metrics that better reflect financially material human rights risks.
Appendices:
Endnotes:
[1] Rights CoLab and the DfG team are grateful for the suggestions of Michael Hamby and Mahdu Mathew of SASB; Ryan Roser and Yang Ruan of Factset’s TruValue Labs; Adriana Bora, Yolanda Lannquist, Nicolas Miailhe, and Nyasha Weinberg of the Bingham Centre for the Rule of Law; and Arianne Griffith, Hannah Lerigo-Stephens, and Emily Wyman of Rights Lab.
[2] For further details on the other methods tested, please see the Spring 2021 report.
[3]The other metrics are: “Employee engagement as a percentage,” “Voluntary and involuntary turnover rate for executives/senior managers, mid-level managers, professionals, and all other employees,” “Percentage of technical employees who are H-1B visa holders,” “Total amount of monetary losses as a result of legal proceedings associated with employment discrimination,” “Discussion of talent recruitment and retention efforts for scientists and research and development personnel,” “Description of talent recruitment and retention efforts for health care practitioners,” and “Percentage of employees that are foreign nationals and that are located offshore.” Categories of employees may be slightly different for the same metric in different industries – for example, the metric for turnover rates is for “all employees” in the E-Commerce industry and for “(a) executives/senior managers, (b) mid-level managers, (c) professionals, and (d) all others” in the Biotechnology and Pharmaceuticals industry.
[4] Because of inconsistent formatting between 10-Ks, we cannot determine which section each paragraph of text belongs to once we have pulled each 10-K into our dataset. Therefore, it is possible that the text we determine discusses a risk using the risk heuristic is actually not in the “Risk Factors” section of the 10-K.
[5] At the end of 2020, the SEC revised the rule so that starting with the 2022 proxy season investors are required to hold the stock for a minimum of three years. See: Securities and Exchange Commission press release, “SEC Adopts Amendments to Modernize Shareholder Proposal Rule,” September 23, 2021 https://www.sec.gov/news/press-release/2020-220
[6]Maria Ward-Brennan, “ESG keywords on the rise in corporate event transcripts,” Corporate Secretary, August 12, 2021 https://www.corporatesecretary.com/articles/shareholders/32677/esg-keywords-rise-corporate-event-transcripts?utm_source=CS230721&utm_medium=email&utm_campaign=esg_script
[7] Adding a context to the search is necessary when the keyword is ambiguous. For example, for the term “diversity,” adding a context rule is necessary because the word also appears in paragraphs that are irrelevant to our analysis. A Form 10-K may contain paragraphs that are about “diverse portfolios,” for example. On the other hand, the search term “employee diversity” does not require a context because it is almost guaranteed to be relevant to the topic.
[8] We also experimented with the GDELT Events database. Each record in this database represents a single event rather than an article, and the only fields available to search for keywords are the URL of the article and its page title. Although this dataset is smaller and more manageable and provides each event equal weight, we stopped using it after a few preliminary tries since the GKG dataset, which includes information on the theme of an article and the organizations mentioned within it, is better suited to our needs.
[9] The odds-ratio analysis is an extension from DfG team member Alexander Jermann’s independent study, in which he performed the odds-ratio test on a dataset of New York Times and Guardian articles.
[10] We are using the term “ingest” to refer to the process of downloading the data, cleaning it, and making it ready for use in subsequent analyses.
[1] Rights CoLab and the DfG team are grateful for the suggestions of Michael Hamby and Mahdu Mathew of SASB; Ryan Roser and Yang Ruan of Factset’s TruValue Labs; Adriana Bora, Yolanda Lannquist, Nicolas Miailhe, and Nyasha Weinberg of the Bingham Centre for the Rule of Law; and Arianne Griffith, Hannah Lerigo-Stephens, and Emily Wyman of Rights Lab.
Photo by Rene Böhmer on Unsplash

{kind=link}
{kind=link}